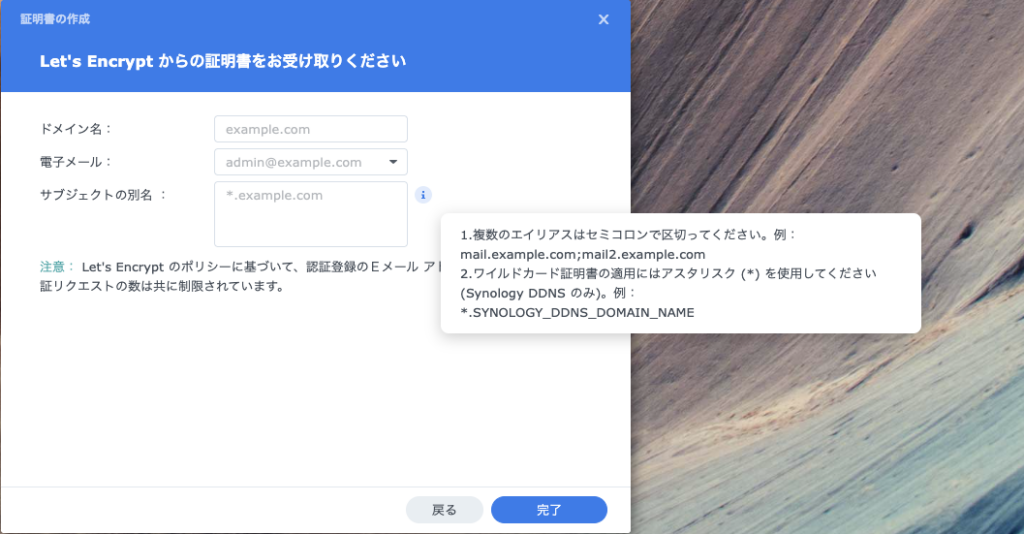
※2026/4/11現在の情報になります
以前よりUbuntuでTV録画・視聴サーバー(以降、TVサーバーと表記)を設置し、CMを抜いたmp4への変換にはWindowsのAmatsukazeを利用し、バックアップ処理も含めて自動化していました。しかし、TVサーバーのために2台のPCを使うのはもったいないと考え、Ubuntu上で完結するシステムへの切り替えを検討していました。
ところがネットを検索しても、録画後にAmatsukazeを使ってCM抜きmp4を生成する自動化処理はWindows単体もしくはWindowsとUbuntuを2台利用したものがほとんどで、Ubuntuのみで完結したシステムの記事は見つかりませんでした。
そこで、TVサーバーをUbuntuで実装する方法を一から検討し、「録画→不要ファイル削除→CM抜き→mp4/tsバックアップ」の手順を完全自動化して、現在メンテナンスフリーで安定運用しています。
本記事はUbuntu上で上記自動化を行ったTVサーバー仕様をメモしたものになります。
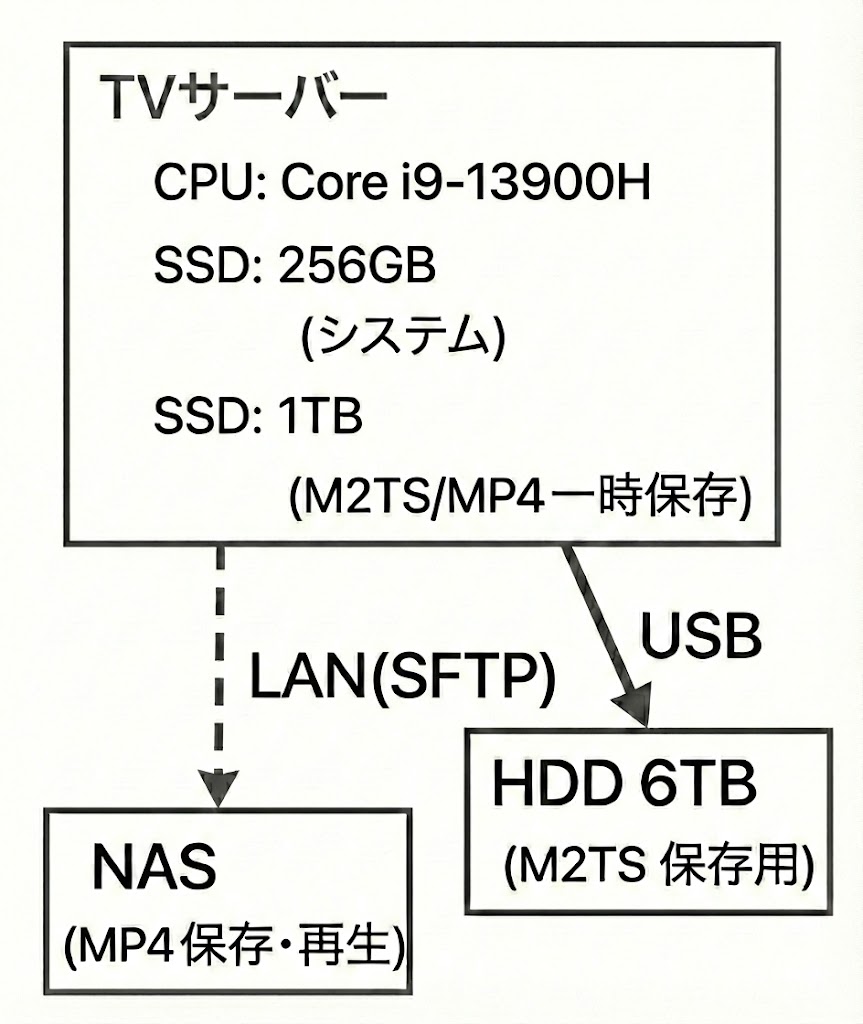
本記事のTVサーバーのシステム構成
構築したTVサーバーのシステム構成は以下のとおりです。
mp4ファイル再生用のメディアサーバーはTVサーバー上に構築することでPC一台でシステムを完結させることもできます。しかし、mp4ファイルは最終的にNASへバックアップコピーするので、録画中のDrop発生要因を減らすことも考慮し、バックアップ先のNAS上で整理・再生するようにしました。
NASへのコピーはSFTPを利用しました。Exportされたディレクトリをマウントする形式だと電源を入れる順番などでマウントに失敗することもあるため、コピー開始直前にNAS側の異常を検知できるSFTPを使っています。
tsファイルはファイルサイズが大きくLAN経由でのコピーは時間がかかる上に、保存後は頻繁にアクセスすることもないことから、NASへのバックアップコピーではなくPCに直接接続したHDDを保存先にしています。
TVサーバー構築用ソフトウェア
TVサーバーを構築するソフトは、録画用に「EPGStation」、リアルタイム視聴・tsファイル再生用に「KonomiTV」を利用します。EPGStationは録画した番組をts形式で保存し、KonomiTVでtsファイルを直接再生して視聴できます。
録画用ソフトにEPGStationを使う理由は、RaspberryPi上でも動作するためです。拙宅ではTVサーバーが何らかのトラブルで録画に失敗する場合に備えてRaspberryPiで録画バックアップサーバーを動かしているため、録画ルール(時刻・条件・録画ファイル格納ディレクトリ)のデータを同期しやすいEPGStationを選択しました。
このような縛りがなければ、KonomiTVが録画予約までサポートしているEDCBを使うほうが便利かと思います。
TVサーバー構築用OS
録画用ソフトにEDCBを使えばWindows PCのみでTVサーバーを構築することはできますが、セキュリティアップデートでアプリが起動しなくなる、録画途中に負荷がかかりDrop発生の可能性がある、再起動が発生する、突発的なブルースクリーンが発生するなどで録画が失敗するリスクがつきまといます。
Ubuntuは自動アップデートなどの自動処理を抑止できる上に、コンソールを使ってファイル操作やログのチェックもできることから、UbuntuでTVサーバーを構築しています。
tsファイルのmp4変換とバックアップ
録画した番組を保存する場合、tsファイルをほかの媒体にコピーするだけで終わります。しかし、tsファイルは下記の点で保存・視聴には不向きです。
100時間で約76GBとなり、1年でTB単位でトータル保存ファイルサイズが増加するため、ストレージコストが高くつく
スマホやタブレットへの保存(オフライン視聴)時に保存できる番組数が少なくなる
tsファイルを直接再生できるプレイヤー・メディアサーバーが少ない
CMや番宣など不要な部分が含まれているため、流し見に向いていない
この問題は、Amatsukazeを利用しCMを抜いたmp4ファイルに変換し、tsの代わりにmp4を保存することで解決できます。mp4に変換するとファイルサイズはおおよそ10-30%程度まで縮小できます。
ただし、mp4に変換するとtsファイルに記録されているオリジナルの字幕情報、ニコニコ動画のコメント、CMなどの付帯情報が消えてしまうため、これらを残したい場合はtsファイルも残しておく必要があります。また、録画予約当初は削除を前提としていても、後になってずっと保存しておきたくなることもあるので、tsファイルもしばらくの間は保持していたほうが安心です。
メンテナンスフリーのための自動処理の要件
録画したファイルを保存する際には、通常下記の作業を行います。
SSD/HDD/NASの残容量確認と不要ファイルの削除
CM抜きmp4ファイルへ変換
NAS,HDDへのコピー
本システムはメンテナンスフリーを目的としているので、これらを自動で行う手順を実装する必要があります。変換、転送処理については処理分岐条件はないため自動化は簡単です。しかし、ファイル・フォルダの整理と不要ファイルの削除については、削除したいファイルとそうでないファイルを分けて考える必要がある上に、保存先のストレージ容量の制約もあります。
これらの制約を踏まえつつ、本システムでは次の方法で自動化しています。
不要ファイルの削除
EPGStationで録画したtsファイルの削除は、EPGStationの削除機能にまかせます。EPGStation以外からファイルを削除してしまうとEGPStationのデータベースとの不整合が発生し、トラブルの原因になるためです。
保存が必要なtsファイルは、自動削除処理が実行される前に外付けHDDへコピーして保存します。コピー先のディレクトリサイズが指定容量を超過していた場合は、指定容量以内に収まるまで更新日時の古いファイルから順番に自動で削除して容量オーバーを回避します。これにより、即削除によるファイルの喪失を防ぎます。最大ディレクトリサイズはディレクトリごとに定義できるようにします。
各録画ファイルへ適用する削除ルールは、EPGStationの録画予約時の保存先ディレクトリ指定機能を利用します。ファイル削除ルールごとにディレクトリを以下の4つに分け、録画時にこれらのディレクトリを指定して録画ファイルを自動で分類します。
no_conversion: CMカットも変換も不要な番組(ニュースなど)delete: 一定期間保持する番組(バラエティ番組など)delete_after_watch: 視聴するまで自動消去しない番組(連続ドラマなど)keep: 再エンコードに備えてtsを残したい番組(映画など)
NAS上のmp4ファイルについてもtsファイルと同様のルールで削除し、コピー開始前にルールに従って削除します。
ファイル削除によって空ディレクトリもできるため、HDDコピー時に空ディレクトリも削除する処理を実行するようにします。
mp4ファイルへの変換
CMカット機能があるAmatsukazeを使用します。AmatsukazeはUbuntuに対応しているため、Ubuntu上で動作させます。
変換したmp4ファイルを格納するディレクトリはtsファイルと同じ構造を維持するようにし、管理の手間を省きます。ここでは/mnt/converted_filesに保存するものとします。
NAS・HDDへコピー
Pythonスクリプトで以下のように処理をします。
tsファイル: 直接接続された外付けHDDへコピーmp4ファイル: sftp経由でNASへアップロード
一度変換・コピーしたファイルは繰り返し同じ処理が走らないようにデータベースに記録し管理します。
ファイルをコピーする際には録画ファイルのディレクトリ構造を維持してコピーし、ファイル整理の管理の手間を省きます。
TVサーバー構築
必要なPCスペック
録画・再生だけであればN100等の低スペックPCでも可能ですが、Amatsukazeでの変換を裏で同時に行う場合はCPU性能が必要になります。
Core i9のミニPCをTVサーバーにして運用した場合、変換中に録画ファイルのDropは発生しておらず、1時間番組の場合ですと録画終了からNASへのアップロード完了までは10分程度で終わります。
N100の場合は同時録画をしている最中に変換処理をしているとDropが発生することがありますが、変換処理を深夜などの無録画時間帯で実行することで回避できます。
メモリは8GBでも問題はないですが、選択するCodecやアップデートによって使用メモリが増えることもあるので、Swap発生を抑えるためにも16GBは搭載していた方が安心です。
Ubuntuのインストール
インストールするPCによりインストール方法が変わるため、ここでの説明は割愛します。以下の記事などを参照してください。
EPGStation、KonomiTVのセットアップ
EPGStationとKonomiTVをUbuntuにインストールする方法は以下の記事にまとめていますので、こちらを参考にしてください。
ECDBは下記記事を参考にするとインストールできます。
【2023年10月】Ubuntu + Mirakurun + EDCB-Wine + KonomiTV (px4_drv + recisdb + ISDBScanner) でパパッと Linux 録画鯖構築の手引き
Ubuntu上で動作するAmatsukazeをセットアップする
Amatsukazeのインストールや設定は環境に大きく依存するので、マニュアル を参考にしてインストールしてください。
Amatsukazeのセットアップ後、最終的に以下のコマンドで変換キューに追加し、出力先にmp4ファイルができていればよいです。
$ /home/ユーザー名/Amatsukaze/exe_files/AmatsukazeAddTask -f <tsファイル> -o <出力先ディレクトリ> -ip localhost -s <プロファイル名>変換が行われているかどうかはAmatsukazeのWebUI(http://localhost:32769)で確認します。
変換に失敗している場合はログを見て原因を探り解決します。
Amatsukazeはサーバー・クライアント型のアプリなので、PC起動時にAmatsukazeServer.shを自動実行し、Amatsukazeサーバーを起動しておく必要があります。これはcrontabに以下の記述を追加すればよいです。
@reboot cd /home/tv-recorder/Amatsukaze/Amatsukaze && ./AmatsukazeServer.sh &自動処理用Pythonスクリプト
次のスクリプトは上記要件を取り入れたPythonスクリプトになります。Windowsでも動作すると思いますが、動作は未確認です。
スクリプトは1ファイルに収めたので、処理内容の確認やカスタマイズはGeminiやCopilotなどを利用して解析・修正していく方法が良いと思います。
環境依存パラメータについては、ファイル先頭に定義されているConfigクラスにまとめていますので、環境に応じて変更してください。年末によく放送されている6時間級の長時間番組録画を考慮するとtsファイルの保存先の最大ファイルサイズはHDDの空き容量が100GB以上、mp4の保存先は25GB以上にしておくと安心です。
【重要】スクリプトにはファイル一括削除処理が入っているため、パラメーターを間違えたりバグによって意図しないファイルを削除することがあります。スクリプト利用の際には、DryRunで十分に動作を理解・確認してください。デフォルトで「dry_run: bool = True」としています。動作確認後にFalse設定にしてください。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
TV録画統合管理スクリプト (Integrated TV Recorder Manager)
【構成】
- Config: 設定管理
- StateManager: 状態管理 (INI)
- DiskOperations (Abstract): ディスク操作の抽象化
- LocalDiskOperations: ローカル操作
- RemoteDiskOperations: SFTP操作
- Cleaner: ディスクの掃除・容量管理ロジック
- Pipelines:
- TsConverterPipeline (Phase 1)
- Mp4UploadPipeline (Phase 2)
- TsBackupPipeline (Phase 3)
- Logger: 条件付きバッファリングロガー
"""
import configparser
import shutil
import subprocess
import logging
import logging.handlers
import sys
import unicodedata
import fcntl
import posixpath
import stat
import re
import time
import os
from abc import ABC, abstractmethod
from pathlib import Path
from datetime import datetime, timedelta
from dataclasses import dataclass, field
from typing import List, Dict, Generator, Optional, Tuple, Any, Union
try:
import paramiko
except ImportError:
print("【エラー】'paramiko' ライブラリが必要です: pip install paramiko", file=sys.stderr)
sys.exit(1)
# =========================================================
# 0. データ構造 & ユーティリティ
# =========================================================
@dataclass
class FileEntry:
path: Union[Path, str]
name: str
size: int
mtime: datetime
def format_bytes(size: int) -> str:
for unit in ["Byte", "KB", "MB"]:
if size < 1024:
return f"{size:.2f}{unit}" if unit != "Byte" else f"{size}{unit}"
size /= 1024
return f"{size:.2f}GB"
def normalize_str(s: str) -> str:
return unicodedata.normalize('NFC', s) if isinstance(s, str) else s
# =========================================================
# 1. 設定管理 (Configuration)
# =========================================================
@dataclass
class Config:
# --- パス設定 ---
source_dir_ts: Path = Path("/mnt/tv-recorder/recorded_files")
dest_dir_hdd: Path = Path("/mnt/hdd/ts_files")
converted_dir: Path = Path("/mnt/converted_files")
ini_file: Path = Path("/home/tv-recorder/Scripts/status_TvRecorder.ini")
log_file: Path = Path("/home/tv-recorder/Scripts/process_TvRecorder.log")
lock_file: Path = Path("/tmp/TvRecorder.lock")
# --- 動作設定 ---
dry_run: bool = True
write_log: bool = False
scan_threshold_sec: int = 10
ts_delete_days: int = 30
# --- HDDコピー実行許可時間帯 ---
copy_window_start_hour: int = 4
# --- NAS接続設定 ---
nas_config: Dict = field(default_factory=lambda: {
'host': '192.168.1.2',
'port': 22,
'user': 'tv-recorder',
'password': '********',
'key_file': None,
'dest_dir': '/tv_program/converted_files'
})
# --- 除外設定 ---
skip_folders_ts: List[str] = field(default_factory=lambda: ['no_conversion'])
hdd_exclude_dirs: List[str] = field(default_factory=lambda: ['keep'])
converted_exclude_dirs: List[str] = field(default_factory=list)
nas_exclude_dirs: List[str] = field(default_factory=lambda: ['/keep/', '/delete_after_watch/'])
# --- 容量上限設定 (GB) ---
max_size_hdd_gb: float = 4500.0
max_size_converted_gb: float = 150.0
max_size_nas_gb: float = 4000.0
# --- 保持ポリシー ---
retention_policies_hdd: List[Dict] = field(default_factory=lambda: [
{"dir": "delete_after_watch", "days": 365, "limit_gb": 1500},
{"dir": "delete", "days": 182, "limit_gb": 3000}
])
retention_policies_nas: List[Dict] = field(default_factory=lambda: [
{"dir": "delete", "days": 365, "limit_gb": 2000},
])
# --- Amatsukaze設定 ---
amatsukaze_cmd: str = "/home/tv-recorder/Amatsukaze/Amatsukaze/exe_files/AmatsukazeAddTask"
amatsukaze_ip: str = "localhost"
amatsukaze_service: str = "QsvEnc"
@property
def is_hdd_copy_time_window(self) -> bool:
return datetime.now().hour == self.copy_window_start_hour
# =========================================================
# 2. ロガー & 状態管理 & 排他制御
# =========================================================
class ConditionalBufferHandler(logging.Handler):
def __init__(self, log_file: Path):
super().__init__()
self.buffer = []
self.passthrough = False
if not log_file.parent.exists():
log_file.parent.mkdir(parents=True, exist_ok=True)
self.stream_handler = logging.StreamHandler(sys.stdout)
self.file_handler = logging.FileHandler(log_file, encoding='utf-8')
def setFormatter(self, fmt):
super().setFormatter(fmt)
self.stream_handler.setFormatter(fmt)
self.file_handler.setFormatter(fmt)
def emit(self, record):
if getattr(self, 'passthrough', False):
self.stream_handler.handle(record)
self.file_handler.handle(record)
else:
if not hasattr(self, 'buffer'):
self.buffer = []
self.buffer.append(record)
def flush_all(self, should_write: bool):
if should_write:
self.passthrough = True
if hasattr(self, 'buffer'):
for record in self.buffer:
self.stream_handler.handle(record)
self.file_handler.handle(record)
self.stream_handler.flush()
self.file_handler.flush()
self.buffer = []
def close(self):
self.stream_handler.close()
self.file_handler.close()
super().close()
def setup_logger(log_path: Path) -> ConditionalBufferHandler:
root = logging.getLogger()
if root.hasHandlers(): root.handlers.clear()
root.setLevel(logging.INFO)
fmt = logging.Formatter('%(asctime)s [%(levelname)s] %(message)s', datefmt='%Y-%m-%d %H:%M:%S')
handler = ConditionalBufferHandler(log_path)
handler.setFormatter(fmt)
root.addHandler(handler)
return handler
def activate_realtime_log():
root = logging.getLogger()
for h in root.handlers:
if isinstance(h, ConditionalBufferHandler):
h.flush_all(True)
def acquire_lock(lock_path: Path):
try:
lock_fd = open(lock_path, 'w')
fcntl.flock(lock_fd, fcntl.LOCK_EX | fcntl.LOCK_NB)
return lock_fd
except IOError:
return None
class StateManager:
SECTION_COPY_HDD = 'CopyHDD'
SECTION_CONVERT = 'Convert'
SECTION_UPLOAD_NAS = 'UploadNAS'
def __init__(self, ini_path: Path):
self.ini_path = ini_path
self.config = configparser.ConfigParser(delimiters=('\t',))
self.config.optionxform = str
self._load()
def _load(self):
if self.ini_path.exists():
try:
self.config.read(self.ini_path, encoding='utf-8')
except Exception: pass
for sec in [self.SECTION_COPY_HDD, self.SECTION_CONVERT, self.SECTION_UPLOAD_NAS]:
if sec not in self.config: self.config[sec] = {}
def is_recorded(self, section: str, file_name: str, file_size: int) -> bool:
if section not in self.config: return False
norm_name = normalize_str(file_name)
sec_data = {normalize_str(k): v for k, v in self.config[section].items()}
return sec_data.get(norm_name) == str(file_size)
def is_key_exists(self, section: str, file_name: str) -> bool:
if section not in self.config: return False
norm_name = normalize_str(file_name)
return norm_name in {normalize_str(k) for k in self.config[section].keys()}
def update_entry(self, section: str, file_name: str, file_size: int, dry_run: bool = False):
if dry_run:
logging.info(f" [DryRun] INI更新 [{section}]: {file_name}")
return
try:
sec_data = self.config[section]
if file_name not in sec_data:
items = list(sec_data.items())
sec_data.clear()
sec_data[file_name] = str(file_size)
for k, v in items: sec_data[k] = v
else:
sec_data[file_name] = str(file_size)
with open(self.ini_path, 'w', encoding='utf-8') as f:
self.config.write(f)
except Exception as e:
logging.error(f"INI Update Failed: {e}")
# =========================================================
# 3. ディスク操作の抽象化 (Disk Operations & Cleaner)
# =========================================================
class DiskOperations(ABC):
@abstractmethod
def list_files_recursive(self, root_dir: Union[Path, str], exclude_dirs: List[str] = None) -> Generator[FileEntry, None, None]:
pass
@abstractmethod
def delete_file(self, path: Union[Path, str]) -> bool:
pass
@abstractmethod
def remove_empty_dir(self, path: Union[Path, str]) -> bool:
pass
@abstractmethod
def exists(self, path: Union[Path, str]) -> bool:
pass
class LocalDiskOperations(DiskOperations):
def __init__(self, dry_run: bool):
self.dry_run = dry_run
def list_files_recursive(self, root_dir: Path, exclude_dirs: List[str] = None) -> Generator[FileEntry, None, None]:
exclude_dirs = exclude_dirs or []
excludes = [root_dir / d for d in exclude_dirs]
for p in root_dir.rglob('*'):
if p.is_file():
if any(ex in p.parents for ex in excludes): continue
yield FileEntry(
path=p, name=p.name, size=p.stat().st_size,
mtime=datetime.fromtimestamp(p.stat().st_mtime)
)
def delete_file(self, path: Path) -> bool:
size_str = "Unknown"
try:
size_str = format_bytes(path.stat().st_size)
except Exception: pass
if self.dry_run:
logging.info(f" [DryRun] 削除: {path} ({size_str})")
return True
try:
path.unlink()
logging.info(f" 削除: {path} ({size_str})")
return True
except Exception: return False
def remove_empty_dir(self, path: Path) -> bool:
if self.dry_run: return True
try:
path.rmdir()
return True
except OSError: return False
def exists(self, path: Path) -> bool:
return path.exists()
class RemoteDiskOperations(DiskOperations):
def __init__(self, sftp, dry_run: bool):
self.sftp = sftp
self.dry_run = dry_run
def list_files_recursive(self, root_dir: str, exclude_dirs: List[str] = None) -> Generator[FileEntry, None, None]:
exclude_markers = exclude_dirs or []
try:
for path, attr, is_dir in self._sftp_walk(root_dir):
if not is_dir:
if any(m in path for m in exclude_markers): continue
yield FileEntry(
path=path, name=posixpath.basename(path), size=attr.st_size,
mtime=datetime.fromtimestamp(attr.st_mtime)
)
except Exception: pass
def delete_file(self, path: str) -> bool:
size_str = "Unknown"
try:
size_str = format_bytes(self.sftp.stat(path).st_size)
except Exception: pass
if self.dry_run:
logging.info(f" [DryRun] 削除(NAS): {posixpath.basename(path)} ({size_str})")
return True
try:
self.sftp.remove(path)
logging.info(f" 削除(NAS): {posixpath.basename(path)} ({size_str})")
if path.endswith('.mp4'):
ass = str(Path(path).with_suffix('.ass'))
if self.exists(ass):
self.sftp.remove(ass)
return True
except Exception: return False
def remove_empty_dir(self, path: str) -> bool:
if self.dry_run: return True
try:
self.sftp.rmdir(path)
return True
except Exception: return False
def exists(self, path: str) -> bool:
try:
self.sftp.stat(path)
return True
except FileNotFoundError: return False
def _sftp_walk(self, remote_path):
try:
for attr in self.sftp.listdir_attr(remote_path):
full_path = posixpath.join(remote_path, attr.filename)
if stat.S_ISDIR(attr.st_mode):
yield from self._sftp_walk(full_path)
yield (full_path, attr, True)
else:
yield (full_path, attr, False)
except Exception: pass
class Cleaner:
def __init__(self, config: Config, ops: DiskOperations, label: str):
self.cfg = config
self.ops = ops
self.label = label
def enforce_size_limit(self, target_dir: Union[Path, str], limit_gb: float, exclude_dirs: List[str], priority_dirs: List[str] = None):
if not self.ops.exists(target_dir): return
all_files = list(self.ops.list_files_recursive(target_dir, exclude_dirs=[]))
total_size = sum(f.size for f in all_files)
original_total_size = total_size
deletable_files = []
for f in all_files:
is_excluded = False
if isinstance(target_dir, Path):
if exclude_dirs and any(ex in f.path.parts for ex in exclude_dirs):
is_excluded = True
else:
if exclude_dirs and any(ex in f.path for ex in exclude_dirs):
is_excluded = True
if not is_excluded:
deletable_files.append(f)
# 優先順位付けロジック: priority_dirs のインデックス順 (小さい方が優先度低)
p_dirs = priority_dirs or []
def get_priority(f_entry: FileEntry) -> int:
for i, p_dir in enumerate(p_dirs):
if isinstance(f_entry.path, Path):
if p_dir in f_entry.path.parts:
return len(p_dirs) - i
else:
if f"/{p_dir}/" in f_entry.path:
return len(p_dirs) - i
return len(p_dirs) + 1
deletable_files.sort(key=lambda x: (get_priority(x), x.mtime))
limit_bytes = limit_gb * (1024**3)
delete_list = []
if total_size > limit_bytes:
for f in deletable_files:
delete_list.append(f)
total_size -= f.size
if total_size <= limit_bytes: break
if delete_list:
self.cfg.write_log = True
activate_realtime_log()
logging.info(f" {self.label} 現在の全体容量 [{target_dir}]: {format_bytes(original_total_size)}")
logging.info(f" {self.label} 全体容量制限チェック [{target_dir}]: 上限 {limit_gb}GB -> {len(delete_list)}ファイル削除")
for f in delete_list:
self.ops.delete_file(f.path)
def apply_retention_policy(self, parent_dir: Union[Path, str], dir_name: str, days: int, limit_gb: int):
if isinstance(parent_dir, Path):
target = parent_dir / dir_name
else:
target = posixpath.join(parent_dir, dir_name)
if not self.ops.exists(target): return
files = list(self.ops.list_files_recursive(target))
total_size = sum(f.size for f in files)
original_total_size = total_size
cutoff = datetime.now() - timedelta(days=days)
delete_list = [f for f in files if f.mtime < cutoff]
keep_list = [f for f in files if f.mtime >= cutoff]
keep_list.sort(key=lambda x: x.mtime)
limit_bytes = limit_gb * (1024**3)
current_keep_size = sum(f.size for f in keep_list)
while current_keep_size > limit_bytes and keep_list:
target_f = keep_list.pop(0)
delete_list.append(target_f)
current_keep_size -= target_f.size
if delete_list:
self.cfg.write_log = True
activate_realtime_log()
logging.info(f" {self.label} 現在の容量 [{target}]: {format_bytes(original_total_size)}")
logging.info(f" {self.label} ポリシー適用 [{dir_name}]: {len(delete_list)}ファイル削除")
for f in delete_list:
self.ops.delete_file(f.path)
def delete_old_files_by_pattern(self, target_dir: Union[Path, str], days: int, pattern: str):
if not self.ops.exists(target_dir): return
all_files = self.ops.list_files_recursive(target_dir)
cutoff = datetime.now() - timedelta(days=days)
delete_list = []
for f in all_files:
if isinstance(target_dir, Path):
if not f.path.match(pattern): continue
else:
if not f.name.endswith('.ts'): continue
if f.mtime < cutoff:
delete_list.append(f)
if delete_list:
self.cfg.write_log = True
activate_realtime_log()
logging.info(f" {self.label} 古いファイルの削除チェック: {target_dir} ({days}日以上, {pattern})")
count = 0
for f in delete_list:
if self.ops.delete_file(f.path):
count += 1
if isinstance(f.path, Path) and f.name.endswith('.ts'):
avs_path = f.path.with_name(f.name + ".trim.avs")
if self.ops.exists(avs_path):
self.ops.delete_file(avs_path)
logging.info(f" -> {count}ファイル削除")
# =========================================================
# 4. パイプライン基底クラス
# =========================================================
class BasePipeline(ABC):
def __init__(self, config: Config, state: StateManager):
self.cfg = config
self.state = state
self.ops = LocalDiskOperations(config.dry_run)
self.cleaner = Cleaner(config, self.ops, "[Local]")
@abstractmethod
def run(self):
pass
def _cleanup_empty_dirs_local(self, root: Path, excludes: List[str] = None):
if not root.exists(): return
excludes = excludes or []
deleted_count = 0
all_dirs = sorted([p for p in root.rglob('*') if p.is_dir()], key=lambda p: len(p.parts), reverse=True)
exclude_paths = [root / e for e in excludes]
for d in all_dirs:
if d in exclude_paths or d == root: continue
try:
if not any(d.iterdir()):
if self.ops.remove_empty_dir(d):
logging.info(f" [Local] 空ディレクトリ削除: {d}")
deleted_count += 1
except OSError: pass
if deleted_count > 0:
self.cfg.write_log = True
activate_realtime_log()
# =========================================================
# 5. 各フェーズの実装
# =========================================================
class TsConverterPipeline(BasePipeline):
"""Phase 1: TS -> MP4 変換"""
def run(self):
tasks = list(self._scan())
self._cleanup()
if tasks:
self.cfg.write_log = True
activate_realtime_log()
logging.info("=== Phase 1: TS変換 (Converter) ===")
logging.info(f"変換対象数: {len(tasks)}")
for task in tasks:
self._process(task)
def _scan(self):
if not self.cfg.source_dir_ts.exists(): return
threshold = datetime.now() - timedelta(seconds=self.cfg.scan_threshold_sec)
seen_names = set()
for p in self.cfg.source_dir_ts.rglob('*.ts'):
if not p.is_file(): continue
# .Trash-* フォルダ内のファイルは除外
if any(part.startswith('.Trash-') for part in p.parts):
continue
if p.name in seen_names:
continue
seen_names.add(p.name)
try:
rel = p.relative_to(self.cfg.source_dir_ts)
if len(rel.parts) > 1 and rel.parts[0] in self.cfg.skip_folders_ts: continue
except ValueError: pass
if datetime.fromtimestamp(p.stat().st_mtime) >= threshold: continue
if self.state.is_recorded(StateManager.SECTION_CONVERT, p.name, p.stat().st_size):
continue
yield {'src': p, 'rel': rel, 'size': p.stat().st_size}
def _cleanup(self):
self.cleaner.enforce_size_limit(self.cfg.converted_dir, self.cfg.max_size_converted_gb, self.cfg.converted_exclude_dirs)
self._cleanup_empty_dirs_local(self.cfg.converted_dir)
def _process(self, task):
src = task['src']
logging.info(f"[Converter] 登録: {src.name} ({format_bytes(task['size'])})")
out_dir = self.cfg.converted_dir / task['rel'].parent
if self._prepare_out_dir(out_dir, src.stem) and self._exec_amatsukaze(src, out_dir):
log_file = out_dir / f"{src.stem}-enc.log"
try:
if not self.cfg.dry_run:
log_file.touch()
logging.info(f" -> エンコードログファイル作成: {log_file.name}")
except Exception as e:
logging.warning(f" -> エンコードログファイル作成失敗: {e}")
self.state.update_entry(StateManager.SECTION_CONVERT, src.name, task['size'], self.cfg.dry_run)
def _prepare_out_dir(self, out_dir, stem):
if self.cfg.dry_run: return True
try:
out_dir.mkdir(parents=True, exist_ok=True)
norm = normalize_str(stem)
for p in out_dir.iterdir():
if p.is_file() and normalize_str(p.stem).startswith(norm): p.unlink()
return True
except Exception: return False
def _exec_amatsukaze(self, src, out_dir):
cmd = [self.cfg.amatsukaze_cmd, "-ip", self.cfg.amatsukaze_ip,
"-s", self.cfg.amatsukaze_service, "-o", str(out_dir), "-f", str(src)]
if self.cfg.dry_run:
logging.info(f" [DryRun] CMD: {cmd}")
return True
try:
subprocess.run(cmd, capture_output=True, text=True, check=True)
return True
except Exception as e:
logging.error(f" -> コマンド失敗: {e}")
return False
class Mp4UploadPipeline(BasePipeline):
"""Phase 2: MP4 -> NAS 転送"""
def __init__(self, config: Config, state: StateManager):
super().__init__(config, state)
self.sftp = None
self.transport = None
def run(self):
if not self.cfg.converted_dir.exists(): return
candidates = list(self._scan_candidates())
if not candidates: return
self.sftp, self.transport = self._connect_sftp()
if not self.sftp:
self.cfg.write_log = True
activate_realtime_log()
logging.info("=== Phase 2: MP4転送 (Upload) ===")
logging.error("[NAS] SFTPサーバーへの接続に失敗しました。転送処理をスキップします。")
return
self.ops = RemoteDiskOperations(self.sftp, self.cfg.dry_run)
self.cleaner = Cleaner(self.cfg, self.ops, "[NAS]")
try:
self._cleanup()
# 実際にアップロードするタスクのみを抽出
tasks_to_process = []
for task in candidates:
if self._check_remote_status(task):
tasks_to_process.append(task)
# 本当に処理するタスクがある場合のみログを有効化・バナー出力
if tasks_to_process:
self.cfg.write_log = True
activate_realtime_log()
logging.info("=== Phase 2: MP4転送 (Upload) ===")
processed = 0
for task in tasks_to_process:
self._process(task)
processed += 1
if processed > 0:
logging.info(f"MP4転送完了数: {processed}")
finally:
if self.transport: self.transport.close()
def _connect_sftp(self):
c = self.cfg.nas_config
try:
t = paramiko.Transport((c['host'], c['port']))
if c['key_file']:
k = paramiko.RSAKey.from_private_key_file(c['key_file'])
t.connect(username=c['user'], pkey=k)
else:
t.connect(username=c['user'], password=c['password'])
return paramiko.SFTPClient.from_transport(t), t
except Exception: return None, None
def _scan_candidates(self) -> Generator[Dict, None, None]:
dest_root = self.cfg.nas_config['dest_dir']
threshold = datetime.now() - timedelta(seconds=self.cfg.scan_threshold_sec)
exclude_ptn = re.compile(r'-\d+$')
seen_names = set()
for p in self.cfg.converted_dir.rglob('*.mp4'):
if not p.is_file(): continue
# .Trash-* フォルダ内のファイルは除外
if any(part.startswith('.Trash-') for part in p.parts):
continue
if p.name in seen_names:
continue
seen_names.add(p.name)
if exclude_ptn.search(p.stem): continue
if datetime.fromtimestamp(p.stat().st_mtime) >= threshold: continue
size = p.stat().st_size
if self.state.is_recorded(StateManager.SECTION_UPLOAD_NAS, p.name, size): continue
rel = p.relative_to(self.cfg.converted_dir).as_posix()
dest = posixpath.join(dest_root, rel)
yield {'src': p, 'dest': dest, 'name': p.name, 'size': size, 'type': 'mp4'}
ass = p.with_suffix('.ass')
if ass.exists():
ass_dest = posixpath.join(dest_root, ass.relative_to(self.cfg.converted_dir).as_posix())
yield {'src': ass, 'dest': ass_dest, 'size': ass.stat().st_size, 'type': 'ass'}
def _check_remote_status(self, task) -> bool:
try:
r_size = self.sftp.stat(task['dest']).st_size
if r_size == task['size']:
# すでに同じサイズのファイルがNAS上に存在する場合はスキップし、INIのみ更新
if task['type'] == 'mp4':
self.state.update_entry(StateManager.SECTION_UPLOAD_NAS, task['name'], task['size'], self.cfg.dry_run)
return False
task['reason'] = "サイズ変更(NAS既存)"
return True
except FileNotFoundError:
task['reason'] = "新規"
return True
def _cleanup(self):
root = self.cfg.nas_config['dest_dir']
nas_excludes = self.cfg.nas_exclude_dirs.copy()
priority_dirs = []
for pol in self.cfg.retention_policies_nas:
self.cleaner.apply_retention_policy(root, pol['dir'], pol['days'], pol['limit_gb'])
priority_dirs.append(pol['dir'])
self.cleaner.enforce_size_limit(root, self.cfg.max_size_nas_gb, nas_excludes, priority_dirs)
self._cleanup_empty_dirs_remote(root)
def _cleanup_empty_dirs_remote(self, root: str):
dirs = []
try:
for path, _, is_dir in self.ops._sftp_walk(root):
if is_dir: dirs.append(path)
except Exception: return
dirs.sort(key=lambda s: len(s), reverse=True)
norm_root = root.rstrip('/')
count = 0
for d in dirs:
if posixpath.dirname(d.rstrip('/')) == norm_root: continue
if self.ops.remove_empty_dir(d):
logging.info(f" [NAS] 空ディレクトリ削除: {d}")
count += 1
if count > 0:
self.cfg.write_log = True
activate_realtime_log()
def _process(self, task):
dest_dir = posixpath.dirname(task['dest'])
logging.info(f"[NAS] Upload ({task['reason']}): {task['src'].name} -> {dest_dir}")
if self._upload(task['src'], task['dest']):
if task['type'] == 'mp4':
self.state.update_entry(StateManager.SECTION_UPLOAD_NAS, task['name'], task['size'], self.cfg.dry_run)
def _upload(self, src, dest):
if self.cfg.dry_run:
logging.info(" [DryRun] Uploaded.")
return True
try:
self._mkdir_p(posixpath.dirname(dest))
size_str = format_bytes(src.stat().st_size)
logging.info(f" -> Upload開始 ({size_str})")
start = time.time()
self.sftp.put(str(src), dest)
dur = time.time() - start
logging.info(f" -> Upload完了 (所要時間: {dur:.1f}秒)")
return True
except Exception as e:
logging.error(f" -> Upload失敗: {e}")
return False
def _mkdir_p(self, remote_dir):
if remote_dir in ['/', '.']: return
try: self.sftp.stat(remote_dir)
except FileNotFoundError:
self._mkdir_p(posixpath.dirname(remote_dir))
try: self.sftp.mkdir(remote_dir)
except OSError: pass
class TsBackupPipeline(BasePipeline):
"""Phase 3: TS -> HDD バックアップ"""
def run(self):
if not self.cfg.is_hdd_copy_time_window and not self.cfg.dry_run: return
tasks = list(self._scan())
self._cleanup()
if tasks:
self.cfg.write_log = True
activate_realtime_log()
dest_path = self.cfg.dest_dir_hdd
pre_size_str = self._get_dir_size_str(dest_path)
logging.info("=== Phase 3: TSバックアップ (Backup) ===")
logging.info(f"コピー対象数: {len(tasks)} (現在のディレクトリサイズ [{dest_path}]: {pre_size_str})")
for task in tasks:
self._process(task)
self.cleaner.delete_old_files_by_pattern(self.cfg.source_dir_ts, self.cfg.ts_delete_days, "*.ts")
post_size_str = self._get_dir_size_str(dest_path)
logging.info(f"バックアップ完了後のディレクトリサイズ [{dest_path}]: {post_size_str}")
def _get_dir_size_str(self, target_path: Path) -> str:
if not target_path.exists():
return format_bytes(0)
all_files = self.ops.list_files_recursive(target_path, exclude_dirs=[])
return format_bytes(sum(f.size for f in all_files))
def _scan(self):
if not self.cfg.source_dir_ts.exists(): return
threshold = datetime.now() - timedelta(seconds=self.cfg.scan_threshold_sec)
seen_names = set()
for p in self.cfg.source_dir_ts.rglob('*.ts'):
if not p.is_file(): continue
if any(part.startswith('.Trash-') for part in p.parts):
continue
if p.name in seen_names:
continue
seen_names.add(p.name)
try:
rel = p.relative_to(self.cfg.source_dir_ts)
if len(rel.parts) > 1 and rel.parts[0] in self.cfg.skip_folders_ts: continue
except ValueError: pass
if datetime.fromtimestamp(p.stat().st_mtime) >= threshold: continue
size = p.stat().st_size
dest = self.cfg.dest_dir_hdd / rel
if self.state.is_recorded(StateManager.SECTION_COPY_HDD, p.name, size):
continue
if dest.exists() and dest.stat().st_size == size: continue
yield {'src': p, 'dest': dest, 'size': size, 'rel': rel}
def _cleanup(self):
priority_dirs = []
for pol in self.cfg.retention_policies_hdd:
self.cleaner.apply_retention_policy(self.cfg.dest_dir_hdd, pol["dir"], pol["days"], pol["limit_gb"])
priority_dirs.append(pol["dir"])
self.cleaner.enforce_size_limit(self.cfg.dest_dir_hdd, self.cfg.max_size_hdd_gb, self.cfg.hdd_exclude_dirs, priority_dirs)
# 孤立した(対応する.tsが存在しない).trim.avsの削除を追加
self._cleanup_orphaned_avs()
self._cleanup_empty_dirs_local(self.cfg.source_dir_ts)
self._cleanup_empty_dirs_local(self.cfg.dest_dir_hdd)
def _cleanup_orphaned_avs(self):
if not self.cfg.source_dir_ts.exists(): return
count = 0
for avs_path in self.cfg.source_dir_ts.rglob('*.trim.avs'):
# 対応する .ts ファイルのパスを作成 (末尾の .trim.avs を削除して判定)
ts_path = avs_path.with_name(avs_path.name.replace('.trim.avs', ''))
if not ts_path.exists():
self.cfg.write_log = True
activate_realtime_log()
if self.ops.delete_file(avs_path):
count += 1
if count > 0:
logging.info(f" [Backup] 対応するTSが存在しない孤立したAVSファイルを削除しました: {count}ファイル")
def _process(self, task):
src, dest = task['src'], task['dest']
logging.info(f"[Backup] コピー: {src.name} ({format_bytes(task['size'])})")
if self._copy(src, dest):
self.state.update_entry(StateManager.SECTION_COPY_HDD, src.name, task['size'], self.cfg.dry_run)
src_avs = Path(f"{src}.trim.avs")
dest_avs = Path(f"{dest}.trim.avs")
if src_avs.exists():
if self.cfg.dry_run:
logging.info(f" [DryRun] 既存のAVSファイルをコピー: {src_avs.name}")
else:
try:
shutil.copy2(src_avs, dest_avs)
logging.info(f" -> 既存のAVSファイルをコピー完了: {dest_avs.name}")
except Exception as e:
logging.warning(f" -> AVSファイルコピー失敗: {e}")
else:
self._create_trim_avs(task)
def _create_trim_avs(self, task):
src_stem = task['src'].stem
log_file = self.cfg.converted_dir / task['rel'].parent / f"{src_stem}-enc.log"
if not log_file.exists(): return
avs_file = Path(f"{task['dest']}.trim.avs")
if self.cfg.dry_run:
logging.info(f" [DryRun] AVS作成: {avs_file.name}")
return
try:
trim_line = None
with open(log_file, 'r', encoding='utf-8', errors='ignore') as f:
for line in f:
if "Trim(" in line:
trim_line = line.strip()
break
if trim_line:
with open(avs_file, 'w', encoding='utf-8') as f:
f.write(trim_line)
src_stat = task['src'].stat()
os.utime(avs_file, (src_stat.st_atime, src_stat.st_mtime))
logging.info(f" -> AVS作成完了: {avs_file.name}")
except Exception as e:
logging.warning(f" -> AVS作成失敗: {e}")
def _copy(self, src, dest):
if self.cfg.dry_run:
logging.info(f" [DryRun] Copy to: {dest}")
return True
try:
dest.parent.mkdir(parents=True, exist_ok=True)
if dest.exists(): dest.unlink()
file_size = src.stat().st_size
free_space = shutil.disk_usage(dest.parent).free
if free_space < file_size:
logging.error(f" -> HDD容量不足 (空き: {format_bytes(free_space)}, 必要: {format_bytes(file_size)})")
return False
logging.info(f" -> Copy開始 ({format_bytes(file_size)})")
start = time.time()
shutil.copy2(src, dest)
dur = time.time() - start
logging.info(f" -> Copy完了 (所要時間: {dur:.1f}秒)")
return True
except Exception as e:
logging.error(f" -> Copy失敗: {e}")
return False
# =========================================================
# メイン処理
# =========================================================
def main():
cfg = Config()
lock_fd = acquire_lock(cfg.lock_file)
if lock_fd is None: return
logger = setup_logger(cfg.log_file)
try:
state = StateManager(cfg.ini_file)
mode = "DryRun" if cfg.dry_run else "Production"
# NOTE: 起動と終了のログは cfg.write_log が True になった時(=何らかの処理が行われた時)のみ
# flush_all() 時に一緒に出力される仕組みになっています。
logging.info(f"=== TV Recorder Manager Start [{mode}] ===")
TsConverterPipeline(cfg, state).run()
Mp4UploadPipeline(cfg, state).run()
TsBackupPipeline(cfg, state).run()
logging.info("=== All Finished ===")
except Exception as e:
cfg.write_log = True
logging.exception(f"Unexpected Error: {e}")
finally:
logger.flush_all(cfg.write_log)
logger.close()
if lock_fd: lock_fd.close()
if __name__ == "__main__":
main()
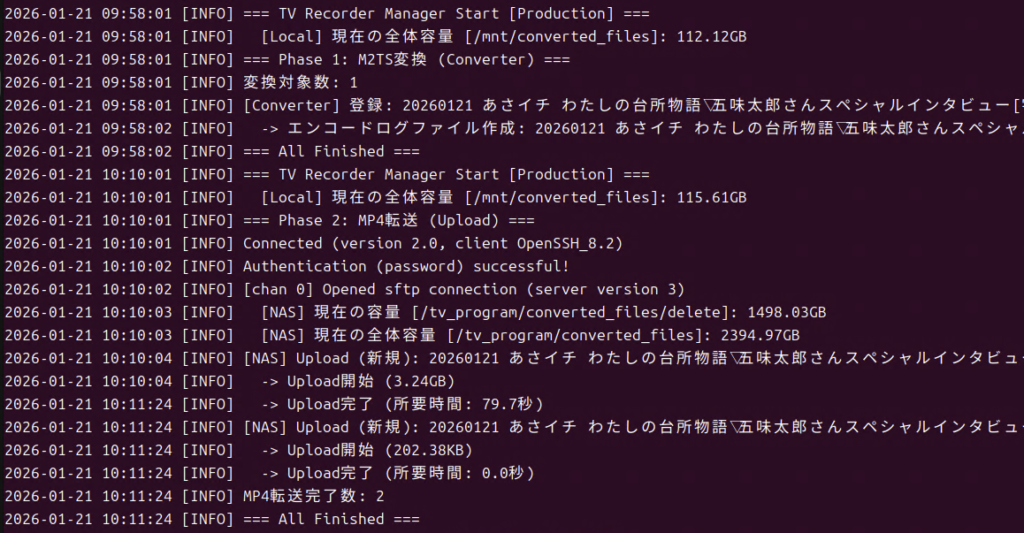
このスクリプトを起動すると下記タスクを順次実行して終了します。
Amatsukazeへ変換タスクを追加
mp4をNASへコピー
tsファイルをHDDへコピー・空ディレクトリの削除
処理対象のファイルがない場合は何もせずに終了します。常駐するタイプのスクリプトではないので、実行開始にはトリガーが必要になります。
実行開始のトリガーはcronを利用します。通常のテレビ番組は0,15,30,45分台に終了することが多いため、録画終了からできるだけ早く変換・コピー処理が始まるように、毎時1分を起点として3分おきに実行するようにします。下記はcrontabの設定例になります。
1-59/3 * * * * /usr/bin/python3 /home/tv-recorder/Scripts/TvRecorder.pyN100などスペックの低いCPUの場合は、録画中に変換処理が走っているとDropが発生することがあるため、変換実行時間を録画番組のない時間帯に限定してスクリプトを起動するように設定すればよいです。
このPythonスクリプトは以下についても考慮しています。
録画中のファイルは処理対象から除外する
ニュースなど、長期に保持する必要がないファイルでHDD/NASの容量を圧迫しないように、最長ファイル保持期間をディレクトリごとに設定できるようにする
HDDアクセスによるDropを避けるため、HDDへコピーする時間帯を制限する
変換・コピー処理のログをリアルタイムでログに保存し、コンソール上からもリアルタイムで動作状況を確認できるようにする
ログの肥大化を避けるため、処理が行われない場合はログ出力しないようにする
実際のファイル操作無しで動作確認できるようにDryRunで動作確認できるようにする
コピー処理実行時にはHDD/NASにコピー可能かどうかを確認し、コピーできない場合はHDD/NASが復帰したときに処理を再実行する
後でCMカット位置を変更できるようにtsファイルコピー時にカット位置を示す*.avsファイルも合わせて生成してtsファイルと同じディレクトリにコピーする(更新日付をtsに合わせています)
変換・コピー後にファイル移動などで再処理が走らないように、処理を実行したファイルをiniファイルに記録し、次回以降の処理でiniファイルを参照してスキップする
TVサーバー稼働後の運用とメンテナンス
KonomiTVはディレクトリ階層構造でファイルをではないため、ディレクトリ構造で整理された1000単位の数の録画ファイルを選択するには不向きです。そこで直近1週間程度の録画番組はKonomiTVで再生し、録画後のCM抜きmp4ファイルの再生や古いファイルはNAS上で動作するJellyfinなどのメディアサーバーを使って視聴します。
録画・変換したファイルは自動で削除されるので短い期間でNASやHDDの容量が足りなくなることはないですが、保存しておく録画ファイルが増えるとHDD/NASを圧迫してシステムが機能しなくなるため、保存するファイルのトータルサイズとHDD/NASの空き容量は、適宜チェックしておく必要があります。
録画予約時に保存するかどうか未定の番組については、いったん削除予定で保存しておき、保存対象になった時点で録画予約の修正と録画変更済みファイルをkeepに移動すればいいです。コピー処理が走らないので、作業はすぐに完了します。
tsファイルの整理はTVサーバーのHDDをSambaで公開状態にして作業するほうがRDPでUbuntuにリモートログインするより効率がよいですが、削除可能な状態で公開することになるため、誤って削除したときにも復帰できるようにゴミ箱機能を有効にしておきます。
sambaのゴミ箱機能を有効化する設定は以下の通りです。
[ts_files]
...
path = /mnt/hdd/ts_files
read only = no
vfs objects = recycle
recycle:repository = .recycle
recycle:keeptree = yes
recycle:versions = yesCode language: PHP ( php ) CMカットのやり直し
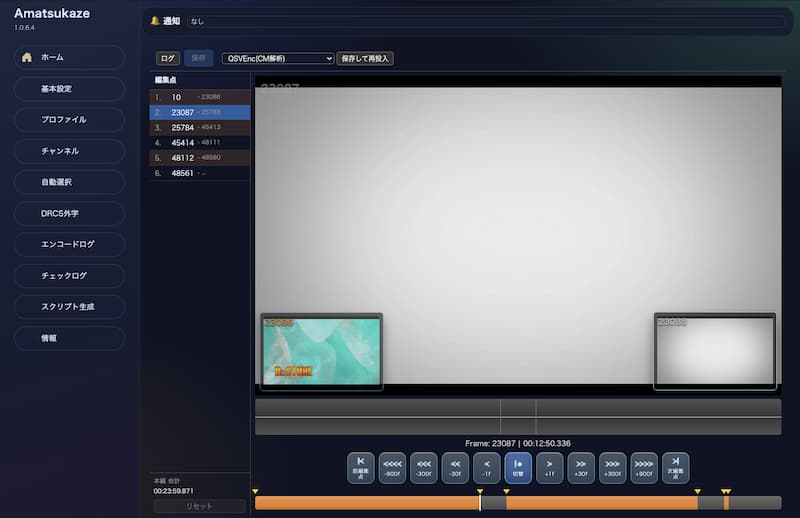
Amatsukazeでtsファイルを変換するとき、tsファイルとavsファイルを同じディレクトリに置いておくことで、強制的にavsファイルの定義に従ってCMがカットされます。
avsファイルはテキストファイルでTrim(<トリミング開始フレーム>,<トリミング終了フレーム>)を「++」で連結することでCM位置がカットできます。以下は定義のサンプルです。
Trim(108,26601) ++ Trim(29299,44403) ++ Trim(48000,53124) ++ Trim(53575,54053)CMのカット位置を変更する場合はこれらの数値を変更・追加・削除して、再変換すればよいことになります。
avsファイルはAmatsukazeのCMカット機能を使うことで生成できます。CMカット目的であれば十分な機能があるので、これを使うことがおすすめです。使用方法はAmatsukazeのマニュアルを参照してください。
そして下記スクリプトを実行すると、avsとtsファイルの更新日付が違うファイルをリストアップし、変換対象ファイルを選択すると、録画ファイルと同様の手順で再変換とNASへの転送を実行します。
import subprocess
import sys
import os
import argparse
import glob
from pathlib import Path
from datetime import datetime
DRY_RUN_MODE = False
ORIGINAL_BASES = [
Path("/mnt/hdd/ts_files").resolve(),
Path("/mnt/tv-recorder/recorded_files").resolve()
]
CONVERTED_BASE = Path("/mnt/converted_files").resolve()
DEFAULT_CLI_PATH = "/home/tv-recorder/Amatsukaze/Amatsukaze/exe_files/AmatsukazeAddTask"
DEFAULT_SERVER_IP = "localhost"
DEFAULT_PROFILE = "QsvEnc"
def get_candidate_files(base_dirs):
candidates = []
for base_dir in base_dirs:
if not base_dir.exists():
print(f"Warning: Directory not found -> {base_dir}")
continue
print(f"Searching for files in {base_dir} ...")
for ts_path in base_dir.rglob("*.ts"):
avs_path = ts_path.with_name(ts_path.name + ".trim.avs")
if avs_path.exists():
ts_stat = ts_path.stat()
avs_stat = avs_path.stat()
if abs(ts_stat.st_mtime - avs_stat.st_mtime) > 1.0:
candidates.append({
"path": ts_path,
"avs_mtime": avs_stat.st_mtime
})
candidates.sort(key=lambda x: x["avs_mtime"])
return candidates
def sync_avs_timestamp(ts_path):
avs_path = ts_path.with_name(ts_path.name + ".trim.avs")
if not avs_path.exists():
return
if DRY_RUN_MODE:
print(f" [DryRun] Would sync timestamp: {avs_path.name}")
else:
try:
stat = ts_path.stat()
os.utime(avs_path, (stat.st_atime, stat.st_mtime))
print(" -> Sync: AVSファイルの更新日時を同期しました")
except Exception as e:
print(f" -> Sync Error: {e}")
def delete_existing_converted_files(target_dir, file_stem):
escaped_stem = glob.escape(file_stem)
pattern = f"{escaped_stem}*.*"
if not target_dir.exists():
return
matched_files = list(target_dir.rglob(pattern))
for f in matched_files:
if DRY_RUN_MODE:
print(f" [DryRun] Would delete: {f.name} (at {f.parent})")
else:
try:
f.unlink()
print(f" -> Deleted: {f.name} (at {f.parent})")
except Exception as e:
print(f" -> Delete Error ({f.name}): {e}")
def convert_single_file(input_file_path, cli_path, server_ip, profile):
try:
input_path = input_file_path
relative_path = None
# どのベースディレクトリに属しているかを判定して相対パスを取得
for base_dir in ORIGINAL_BASES:
try:
relative_path = input_path.relative_to(base_dir)
break
except ValueError:
continue
if relative_path is None:
print(f"[Error] パス解決エラー: {input_path} は指定されたベースディレクトリ内にありません。")
return
output_dir = CONVERTED_BASE / relative_path.parent
print(f"\nProcessing: {input_path.name}")
if not DRY_RUN_MODE:
output_dir.mkdir(parents=True, exist_ok=True)
delete_existing_converted_files(CONVERTED_BASE, input_path.stem)
cmd = [
cli_path,
"-ip", server_ip,
"-f", str(input_path),
"-o", str(output_dir),
"-s", profile
]
if DRY_RUN_MODE:
cmd_str = " ".join(f"'{c}'" if " " in str(c) else str(c) for c in cmd)
print(f" [DryRun] Would run: {cmd_str}")
sync_avs_timestamp(input_path)
else:
subprocess.run(cmd, check=True)
print(" -> Success: タスク登録完了")
sync_avs_timestamp(input_path)
except subprocess.CalledProcessError as e:
print(f" -> Error: コマンド実行失敗 (Code: {e.returncode})")
except Exception as e:
print(f" -> Error: {e}")
def parse_user_selection(user_input, max_len):
if user_input.lower() == 'a':
return list(range(max_len))
selected = set()
parts = user_input.split(",")
for part in parts:
part = part.strip()
if not part:
continue
if "-" in part:
try:
range_parts = part.split("-")
if len(range_parts) == 2:
start = int(range_parts[0])
end = int(range_parts[1])
s, e = min(start, end), max(start, end)
for i in range(s, e + 1):
if 1 <= i <= max_len:
selected.add(i - 1)
except ValueError:
pass
else:
try:
idx = int(part)
if 1 <= idx <= max_len:
selected.add(idx - 1)
except ValueError:
pass
return sorted(list(selected))
def main():
parser = argparse.ArgumentParser(description="Amatsukaze Interactive Converter")
parser.add_argument("-a", "--all", action="store_true", help="確認なしですべての候補を変換します")
args = parser.parse_args()
candidates = get_candidate_files(ORIGINAL_BASES)
if not candidates:
print("条件に一致するファイルが見つかりませんでした。")
return
print(f"\n--- 変換候補リスト (全{len(candidates)}件 / 日時昇順) ---")
for i, item in enumerate(candidates, 1):
print(f"[{i}] {item['path'].name}")
print("----------------------")
selected_indices = []
if args.all:
print("オプション -a が指定されました: 全ファイルを選択します。")
selected_indices = list(range(len(candidates)))
else:
print(f"選択肢: 番号(1-{len(candidates)}), 全選択(a)")
user_input = input(f"変換対象を選択 > ").strip()
if not user_input:
print("選択なし。終了します。")
return
selected_indices = parse_user_selection(user_input, len(candidates))
if not selected_indices:
print("有効な番号が選択されませんでした。")
return
mode_text = "【DryRun】" if DRY_RUN_MODE else "【実行】"
print(f"\n--- {mode_text} 開始 ({len(selected_indices)}件) ---")
for idx in selected_indices:
target_file = candidates[idx]["path"]
convert_single_file(target_file, DEFAULT_CLI_PATH, DEFAULT_SERVER_IP, DEFAULT_PROFILE)
if __name__ == "__main__":
main()参考になれば幸いです。