※2025/9/27 ドイツ語・ハングル講座のダウンロードが完了したにもかかわらず、次回実行で再度ダウンロード処理が実行されるバグを修正しました
2025年9月26日現在、下記の方法でNHKラジオ講座をダウンロードし、時間のあるときに聞いて語学力の維持に努めています。
上記記事のコメントをいただく中で何度か”ニュースで学ぶ「現代英語」”のダウンロードについての要望があったものの、ダウンロードリンクの取得方法がわからず対応を断念していました。
しかし、コメントにてJSON形式でのダウンロードリンクを教えていただき中身を確認したところ、ダウンロードに必要な情報を取得できることがわかりました。
JSON形式はすべての講座についてデータが提供されている点と、XML形式とは異なりJSON形式ではその日の放送のダウンロードリンクが放送直後に拾えるという点で大きなアドバンテージがあります。
そこでXML形式のスクリプトをベースにJSON形式に対応したスクリプトを作成しましたので、ここにメモとして残しておきます。
ストリーミングデータを手動でダウンロードする
自動化のためには、まず手動で最小手順を確認するのが常道です。ダウンロードのための最小手順を以下に示します。
JSONからストリーミングデータのURLとMP3タグ情報を取得する
まず、下記URLへアクセスします。
すると、下記のようなJSONデータを取得できます。(ダウンロードに必要な情報を抜き出して表示しています)
{
"corners": [
...
{
"id": 2686,
"title": "ニュースで学ぶ「現代英語」",
"radio_broadcast": "R2,FM",
"corner_name": "",
"onair_date": "2024年8月16日(金)放送",
"thumbnail_url": "https://www.nhk.or.jp/prog/img/7512/g7512.jpg",
"series_site_id": "77RQWQX1L6",
"corner_site_id": "01"
},
...
]
}Code language: Julia (julia)ここにあるseries_site_idとcorner_site_idを以下のURLフォーマットに当てはめます。
https://www.nhk.or.jp/radio-api/app/v1/web/ondemand/series?site_id=<series_site_id><series_site_id>&corner_site_id=</series_site_id><corner_site_id>Code language: HTML, XML (xml)上記の例の場合、URLは以下のようになります。
このURLにアクセスすると、下記のようなJSONデータを取得できます。(ダウンロードに必要な情報を抜き出して表示しています)
{
...
"episodes": [
...
{
"id": 4050198,
"program_title": "ニュースで学ぶ「現代英語」 東京・恵比寿で36年ぶりビール醸造",
"onair_date": "8月16日(金)午前9:30放送",
"closed_at": "2024年8月23日(金)午前9:45配信終了",
"stream_url": "https://vod-stream.nhk.jp/radioondemand/r/77RQWQX1L6/s/stream_77RQWQX1L6_67ba0d52a82e51ffe68fb4d422f5d4d6/index.m3u8",
"aa_contents_id": "[radio]vod;ニュースで学ぶ「現代英語」 東京・恵比寿で36年ぶりビール醸造;r2,130;2024081671810;2024-08-16T09:30:00+09:00_2024-08-16T09:45:00+09:00",
"program_sub_title": "ニュースや研究の現場で活躍している専門家が、「実際に現場で使っている英語」をニュースの背景とともに解説します。MC:トラウデン直美 解説:竹下隆一郎"
},
...
]
}Code language: JavaScript (javascript)ダウンロードURLは’stream_url’、番組の内容は’aa_contents_id’を’;’で区切ったときの2番めの要素、放送日は’aa_contents_id’を’;’で区切ったときの4番めの要素にあるので、これらを利用してダウンロードし、ファイル名とMP3タグを付与すれば良いことになります。
各番組のストリーミングをmp3ファイルに変換する
ストリーミングファイルのダウンロードにはffmpegを使用します。ffmpegで下記のコマンドラインオプションで起動するとmp3ファイル形式でダウンロードできます。
ffmpeg -http_seekable 0 -i <file_name属性のURL> -c:a mp3 "<mp3のダウンロードパス>"Code language: HTML, XML (xml)下記はコマンドラインの設定例になります。
ffmpeg -http_seekable 0 -i https://vod-stream.nhk.jp/radioondemand/r/7512/s/stream_7512_dc1584c4e6daed4da991f07e04db5005/index.m3u8 -c:a mp3 ".¥ニュースで学ぶ「現代英語」 2024年06月07日放送分.mp3"Code language: JavaScript (javascript)上記コマンドラインはffmpeg 4.4.4と5.1.2で動作を確認しています。
ダウンロード処理を自動化する
上記JSONの情報を利用してダウンロード処理を自動化した方法が下記になります。
自動ダウンロード用Pythonスクリプト
自動化には引き続きPythonを利用しています。Windows/Mac/Linux上で同じファイルで同じ処理をさせることができることと、読みやすく修正しやすいスクリプトを書くことができるためです。下記スクリプトをUTF-8で保存し実行することで、ファイルの変更なしでWindows/Mac/Linux上のPython 3.9で動作することを確認済みです。
import os
import urllib.request
import subprocess
import datetime
from os.path import expanduser
import sys
import json
import unicodedata
def main():
#OS(実行環境)依存のパラメータをセットする
if sys.platform=='win32': #Windows
path_delimiter="\\"
today=datetime.date.today()
download_dir=".\\download"
ffmpeg_bin=".\\win\\ffmpeg.exe"
elif sys.platform=='darwin': #Mac
path_delimiter="/"
today=datetime.date.today()
download_dir=expanduser("~")+"/Downloads/NHK語学講座"
ffmpeg_bin="./mac/ffmpeg"
else: #Linux(Synology-NAS)
path_delimiter="/"
download_dir="/volume1/music/NHK語学講座"
ffmpeg_bin="/volume1/@appstore/ffmpeg/bin/ffmpeg"
#各語学講座のseries/corner ID取得キーワード、講座名、ダウンロード完了済みかどうかをチェックするファイルサイズ、MP3タイトルタグから消去するプレフィックス文字列を定義する
trigger_kouza_size_prefix_filters = []
trigger_kouza_size_prefix_filters += [[ '小学生の基礎英語', '小学生の基礎英語', 4800000, '', [] ]]
trigger_kouza_size_prefix_filters += [[ '中学生の基礎英語 レベル1', '中学生の基礎英語レベル1', 7200000, '', [] ]]
trigger_kouza_size_prefix_filters += [[ '中学生の基礎英語 レベル2', '中学生の基礎英語レベル2', 7200000, '', [] ]]
trigger_kouza_size_prefix_filters += [[ 'エンジョイ・シンプル・イングリッシュ', 'エンジョイ・シンプル・イングリッシュ', 2350000, 'エンジョイ・シンプル・イングリッシュ ', [] ]]
trigger_kouza_size_prefix_filters += [[ 'ラジオビジネス英語', 'ラジオビジネス英語', 7200000, 'ラジオビジネス英語 ', [] ]]
trigger_kouza_size_prefix_filters += [[ 'ラジオ英会話', 'ラジオ英会話', 7200000, 'ラジオ英会話 ', [] ]]
trigger_kouza_size_prefix_filters += [[ '英会話タイムトライアル', '英会話タイムトライアル', 4800000, '英会話タイムトライアル', [] ]]
trigger_kouza_size_prefix_filters += [[ 'ニュースで学ぶ「現代英語」', 'ニュースで学ぶ「現代英語」', 7200000, 'ニュースで学ぶ「現代英語」 ', [] ]]
trigger_kouza_size_prefix_filters += [[ 'まいにち中国語', 'まいにち中国語', 7200000, 'まいにち中国語 ', [] ]]
trigger_kouza_size_prefix_filters += [[ 'まいにちハングル講座', 'まいにちハングル講座', 7160000, 'まいにちハングル講座 ', [] ]]
trigger_kouza_size_prefix_filters += [[ 'まいにちイタリア語', 'まいにちイタリア語【初級編】', 7200000, 'まいにちイタリア語 初級編 ', ['まいにちイタリア語', '初級編' ]]]
trigger_kouza_size_prefix_filters += [[ 'まいにちイタリア語', 'まいにちイタリア語【応用編】', 7200000, 'まいにちイタリア語 応用編 ', ['まいにちイタリア語', '応用編' ]]]
trigger_kouza_size_prefix_filters += [[ 'まいにちドイツ語', 'まいにちドイツ語【初級編】', 7160000, 'まいにちドイツ語 初級編 ', ['まいにちドイツ語', '初級編' ]]]
trigger_kouza_size_prefix_filters += [[ 'まいにちドイツ語', 'まいにちドイツ語【応用編】', 7160000, 'まいにちドイツ語 応用編 ', ['まいにちドイツ語', '応用編' ]]]
trigger_kouza_size_prefix_filters += [[ 'まいにちフランス語', 'まいにちフランス語【初級編】', 7200000, 'まいにちフランス語 初級編 ', ['まいにちフランス語', '初級編' ]]]
trigger_kouza_size_prefix_filters += [[ 'まいにちフランス語', 'まいにちフランス語【応用編】', 7200000, 'まいにちフランス語 応用編 ', ['まいにちフランス語', '応用編' ]]]
trigger_kouza_size_prefix_filters += [[ 'まいにちスペイン語', 'まいにちスペイン語【初級編】', 7200000, 'まいにちスペイン語 初級編 ', ['まいにちスペイン語', '初級編' ]]]
trigger_kouza_size_prefix_filters += [[ 'まいにちスペイン語', 'まいにちスペイン語【応用編】', 7200000, 'まいにちスペイン語 応用編 ', ['まいにちスペイン語', '応用編' ]]]
trigger_kouza_size_prefix_filters += [[ 'まいにちロシア語', 'まいにちロシア語【初級編】', 7200000, 'まいにちロシア語 初級編 ', ['まいにちロシア語', '初級編' ] ]]
trigger_kouza_size_prefix_filters += [[ 'まいにちロシア語', 'まいにちロシア語【応用編】', 7200000, 'まいにちロシア語 応用編 ', ['まいにちロシア語', '応用編' ] ]]
trigger_kouza_size_prefix_filters += [[ 'アラビア語講座', 'アラビア語講座', 7200000, 'アラビア語講座 ', [] ]]
trigger_kouza_size_prefix_filters += [[ 'ポルトガル語講座', 'ポルトガル語講座 ステップアップ', 7200000, 'ポルトガル語講座 ステップアップ ', [] ]]
# ダウンロード先のフォルダがない場合はフォルダを作成する
os.makedirs(download_dir, exist_ok=True)
#各語学講座のseries_site_idとcorner_site_idが記載されているJSONからIDを取得し、各講座のJSONファイルのダウンロードURLを生成する
series_corner_id_url="https://www.nhk.or.jp/radio-api/app/v1/web/ondemand/corners/new_arrivals"
series_corner_id_json = download_dir+"/series_corner_id.json"
urllib.request.urlretrieve(series_corner_id_url, series_corner_id_json)
with open(series_corner_id_json,'r',encoding="utf-8") as f:
series_corner_ids = json.load(f)
os.remove(series_corner_id_json)
for i in range(len(trigger_kouza_size_prefix_filters)):
for series_corner_id in series_corner_ids['corners']:
if series_corner_id['title']==trigger_kouza_size_prefix_filters[i][0] :
series_site_id = series_corner_id['series_site_id']
corner_site_id = series_corner_id['corner_site_id']
trigger_kouza_size_prefix_filters[i][0] = 'https://www.nhk.or.jp/radio-api/app/v1/web/ondemand/series?site_id='+series_site_id+'&corner_site_id='+corner_site_id
break
#各語学講座のストリーミングデータをダウンロードする
for url_kouza_size_prefix_filter in trigger_kouza_size_prefix_filters:
#URL/講座名(=MP3タグ名)/ファイルサイズを格納する
url=url_kouza_size_prefix_filter[0]
kouza=url_kouza_size_prefix_filter[1]
size=url_kouza_size_prefix_filter[2]
title_replace=url_kouza_size_prefix_filter[3]
filter=url_kouza_size_prefix_filter[4]
# print(f"url:{url} / kouza:{kouza} / size:{size} / title_replace:{title_replace} / filter:{filter}")
# JSONコンテンツを読み出す
bangumi_json = download_dir+"/bangumi.json"
urllib.request.urlretrieve(url, bangumi_json)
with open(bangumi_json,'r',encoding="utf-8") as f:
json_dict = json.load(f)
os.remove(bangumi_json)
# ダウンロードしたファイルパスを保持する変数を初期化する
last_download_path_only_date=""
# 各LessonのストリーミングデータをMP3に変換してダウンロードする
for json_element in json_dict['episodes']:
#放送年月日を取得する
datetime_string=json_element['aa_contents_id'].split(";")[3]
month=int(datetime_string[4:6])
day=int(datetime_string[6:8])
year=int(datetime_string[0:4])
if month<4:
nendo=year-1
else:
nendo=year
contents=json_element['aa_contents_id'].split(";")[1]
# print(f"year:{year} / month:{month} / day:{day} / content:{contents}")
##フィルタが定義されており、かつcontentsにフィルタ文字列が含まれていない場合はスキップする
if filter!=[]:
if not all(k in contents for k in filter):
continue
# MP3に埋め込むタグ情報をセットする
content=unicodedata.normalize('NFKC', contents).replace(title_replace, '').replace('\u3000',' ')
tag_title="{0}年{1}月{2}日放送分「{3}」".format(year,str(month).zfill(2),str(day).zfill(2),content).replace('「「','「').replace('」」','」')
tag_year=nendo
tag_album=kouza+"["+str(nendo)+"年度]"
#print(f"tag_title:{tag_title} / tag_year:{tag_year} / tag_album:{tag_album}")
# MP3のダウンロードパスをセットする
download_subdir=download_dir+path_delimiter+kouza+"["+str(nendo)+"年度]"
os.makedirs(download_subdir, exist_ok=True)
download_filename=kouza+" "+"{0}年{1}月{2}日放送分".format(year,str(month).zfill(2),str(day).zfill(2))+".mp3"
download_path=download_subdir+path_delimiter+download_filename
# 同日に放送された番組は特別番組と判断してダウンロードファイルのファイル名にコンテンツ名を付与する
if download_path == last_download_path_only_date :
download_filename=kouza+" "+"{0}年{1}月{2}日放送分".format(year,str(month).zfill(2),str(day).zfill(2))+"_"+content+".mp3"
download_path=download_subdir+path_delimiter+download_filename
else:
last_download_path_only_date = download_path
#print(f"download_path:{download_path}")
# ストリーミングファイルのURLをセットする
download_url=json_element['stream_url']
#print(f"download_url:{download_url}")
# ffmpegのダウンロード処理用コマンドラインを生成する
command_line=f"{ffmpeg_bin}" \
f" -http_seekable 0" \
f" -i {download_url}" \
f" -id3v2_version 3" \
f" -metadata artist=\"NHK\" -metadata title=\"{tag_title}\"" \
f" -metadata album=\"{tag_album}\" -metadata date=\"{tag_year}\"" \
f" -ar 44100 -ab 64k -c:a mp3" \
f" \"{download_path}\""
print(command_line)
# ダウンロード処理を実行する
if( os.path.isfile(download_path)):
# すでにダウンロード済みファイルがある場合
if( os.path.getsize(download_path)<=size ):
#ファイルサイズが想定サイズに満たないときはダウンロード処理を行う
os.remove(download_path)
subprocess.run(command_line,shell=True)
else:
# ダウンロード済みファイルがない場合
# -> ダウンロード処理を行う
subprocess.run(command_line,shell=True)
if __name__ == "__main__":
main()
上記スクリプトはダウンロード処理の自動化の他に以下の処理を追加しています。
- 実行環境でパラメータを自動で変更する処理を追加
- 年度ごとにダウンロードフォルダを分ける処理を追加
- mp3のalbum,title,yearタグに講座情報とコンテンツを追加
- mp3のtitleタグから冗長な情報を削除
- タグ内の全角英数字および記号を半角に変換
- ソートが正しく動作するようにファイル名・タグ名の月日の表示を0でパディングするように修正
- WindowsのExplolerでmp3の再生時間が正しく表示されない問題に対処するため、ffmpegのエンコードオプションに’-ar 44100 -ab 64k’を明示的に追加
- ダウンロード済みのファイルが存在する場合、ダウンロードが不完全かどうかをファイルサイズでチェックして、サイズが足りない場合は再ダウンロードする処理を追加
- ヨーロッパ系言語講座の初級編と応用編を別フォルダに保存する処理を追加
- 同日に別の放送がある場合は2番目以降の放送のファイル名にの後ろに番組名をつけ、同日で2番組以上放送された場合に上書き保存を防ぐ処理を追加
スクリプトはリスト’url_kouza_size_prefix_filter’にセットした講座情報を一つずつ上から下へ処理していくだけなので、プログラミング経験があれば処理内容は理解できると思います。
mp3のタグ名やダウンロード時のフォルダ構成やファイル名など、それぞれの要望に合わせて細かな調整もスクリプトの当該部分を変更するだけで、簡単に対応できます。
ファイルがダウンロード済みの場合はダウンロードをスキップするようにしているので、何度実行してもダウンロードは一回のみになります。この仕様により、毎日定時に自動実行するようにすれば、ネットワークトラブルなどでダウンロードに失敗した場合でも7日間はリトライがかかるため、ダウンロード漏れの可能性を減らすことができます。
Synology NASで自動ダウンロードする
Synology NASは単体でpythonとffmpegを実行することができるので、NAS単体で上記のスクリプトを動作させることができます。
また、SynologyのNASはスケジュール実行が簡単に設定できるので、定期的なダウンロード処理をする手段として使わない手はありません。
しかし、Synologyにデフォルトでインストールされているffmpegのバージョンは4.1.3と大変古く、上記の方法によるダウンロードができません。このため、有志が配布しているffmpegを下記手順でインストールする必要があります。(2025年6月21日現在では7.0.2が最新版になります)
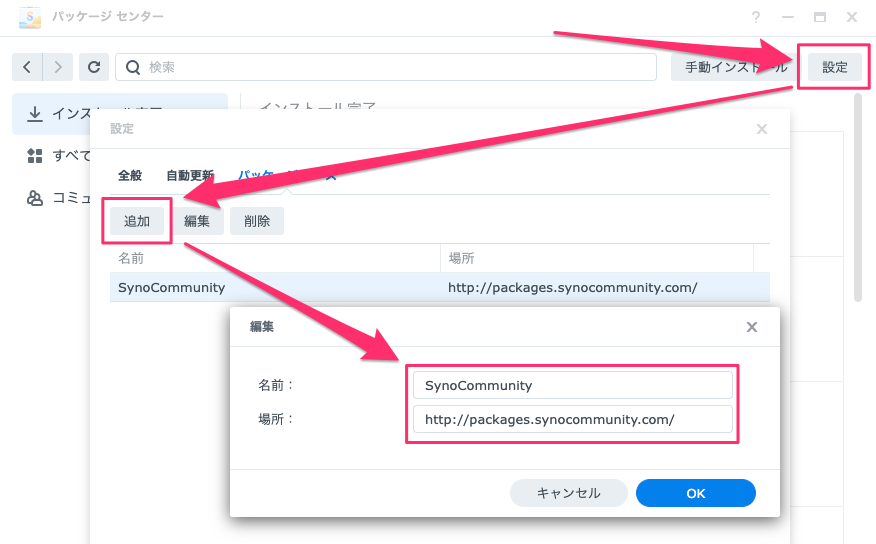
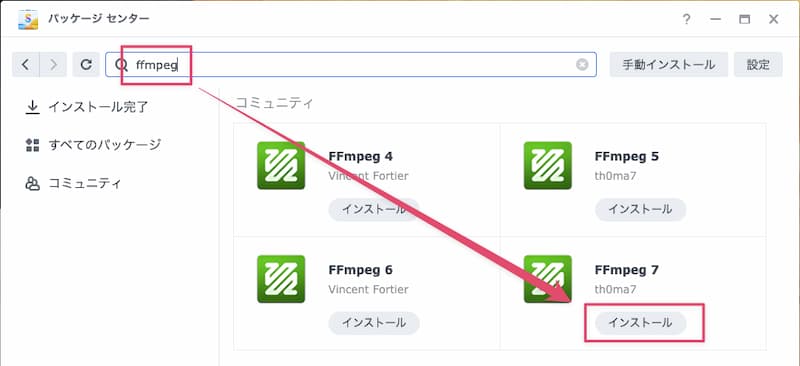
なお、このときにインストールされるffmpegのパスは /volume1/@appstore/ffmpeg/bin/ffmpeg7 になり旧版が上書きされるわけではないので、パスを指定せずにffmpegを呼び出してもここでインストールしたffmpegは起動しません。このため、pythonスクリプトから新たにインストールしたffmpegを起動する場合は絶対パスで指定する必要があります。
ffmpegのデフォルトパスを変更する方法もありますが、スクリプト内で絶対パスで指定するほうがNASシステムへの影響がなく、システムアップデート時に修正が上書きされて修正を元に戻されて動作しなくなるトラブルもないので安全です。
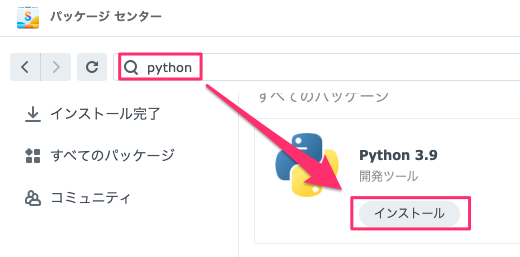
Pythonはパッケージセンターのものを指定してインストールすればいいです。バージョンは3.9以上であれば問題はないと思います。
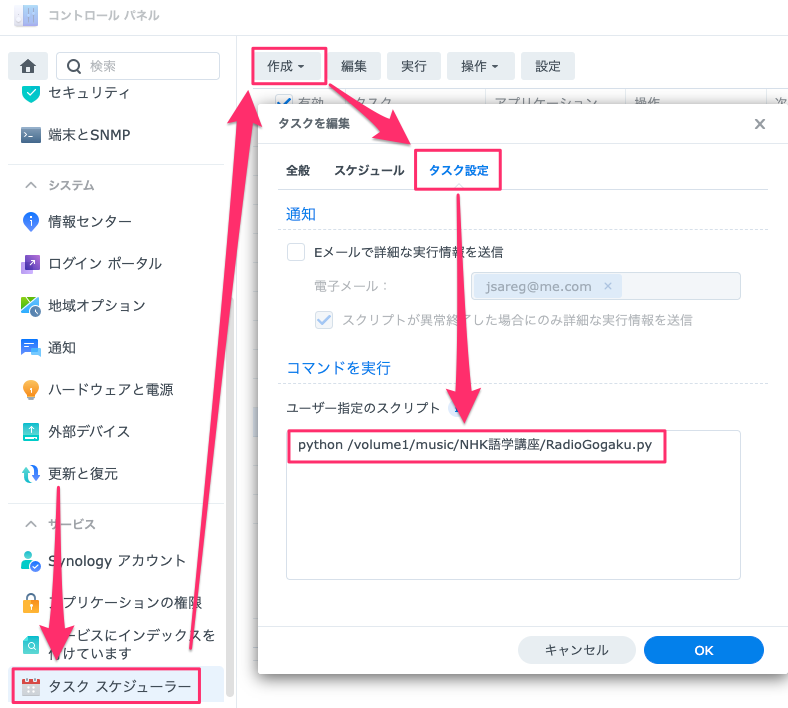
あとはコントロールパネルにあるタスクスケジューラーで定期実行するように設定すれば、スケジュールに従って自動的にダウンロードされるようになります。
正しくダウンロードされたかをチェックする
自動ダウンロード処理が実行されても、自宅のネットワークトラブルやJSON仕様の変更など、様々な要因でダウンロードに失敗する可能性があります。
番組によらずファイルサイズは再生時間に比例するので、WindowsアプリのEverythingを使うなどして最新のダウンロードファイルのファイルサイズを一覧できれば、ファイルサイズがすべて同じかどうかを確認するだけで大丈夫です。ただし、確認のたびにPCを起動しNAS上のフォルダを開いてファイルサイズを確認するというのは手順が多く、毎週定期的に行う作業手順としては少々煩雑です。
私の場合はNASに付属している音楽再生ソフト(Synologyの場合はAudioStation)のスマートプレイリスト(条件にあった曲を自動で検索してリストアップ)を利用して、スマホとPCのブラウザ上でダウンロードチェックできるようにしています。
リスト表示の条件は以下のように設定しています。
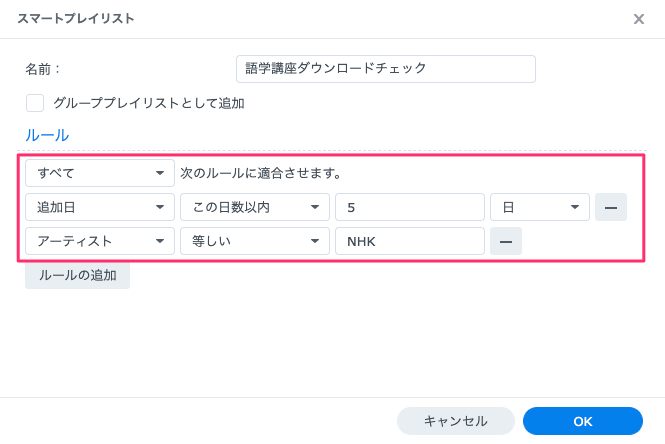
SynologyのAudioStationにはファイルサイズを表示する機能はないので、ファイル再生時間が全て15分になっているかどうかでダウンロードが正しく行われているかを確認しています。
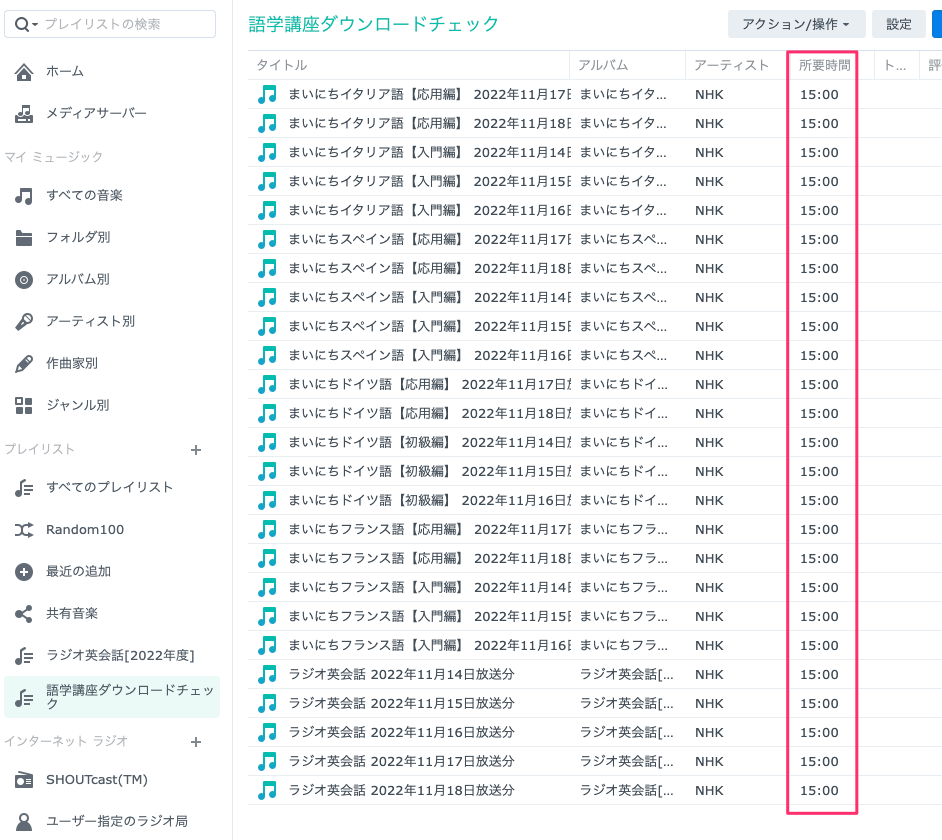
SynologyのAudioStationはスマホアプリもあるので、スマホアプリでこのプレイリストを表示すればどこでもダウンロードチェックができるようになります。
このプレイリスト上でファイルを再生することで自動的にスマホにダウンロードされるので、すぐに講座を聴講することもできて操作の手間を削減できます。
参考になれば幸いです。